
背景:小白是我的一个朋友,他之前是做网站开发的,最近转型做AI工程师了。
有一天,领导找到小白,说测试同学离职了,HC冻结,希望能够在gitlab 中接入AI进行代码审查,发现代码中的缺陷,从而帮助大家提高研发效率。
领导找到一个开源仓库给小白,部署后就可以直接使用。小白的任务是,。
🐬为什么要读论文?
小白是多年的老司机,私有化部署马上就弄好了,但是如何评测可把小白给难倒了,没做过呀?
小白先是谷歌了一番,搜索出来的内容,更多的是最佳实践,具体怎么解决问题,都不够深入。
搜索无果后,小白又问了AI。这次有所改进,AI帮忙找了很多开源仓库(CodeXGLUE、Awesome-Code-Benchmark等)。仓库会告诉你如何使用该仓库。但是对于如何构建数据集、如何评测等问题都没有详细的阐述。小白发现,每个仓库都有个共同点,几乎都有引用论文(Paper)。
小白决定硬着头皮读一下论文,想不到竟然有意外收获。论文详细的介绍了作者是如何构建评测数据、评测指标、不同大模型的对比、提示词、如何构建数据飞轮形成闭环等内容。
小白这才是意识到,。因为AI工程不同于传统的Web开发,不止要了解技术原理,还需要了解AI的工程学、方法论等。而获取信息的最好方式,就是读论文。
🐣如何读论文
以下内容以这篇论文举例:https://arxiv.org/pdf/2401.04621
1、克服语言障碍
读论文的第一个障碍就是语言。看到三四十页密密麻麻的英文,整个人都不好了。还好我们有工具。
:严格来说他一个AI插件。他既可以帮你完成翻译,而且你可以通过向AI提问题来更好的了解论文。

:腾讯出品的AI工具。也许你希望直接阅读英文文章,那你可能需要一个滑词翻译的功能。我使用的是元宝,需要在设置中开启(设置-> 快捷工具 -> 打开“当选中文本时显示工具栏”)。豆包插件不知道为啥不生效。
翻译工具挺多的,就不举例了。
2、论文结构 & 抓重点
语言的障碍克服了,但是几十页的论文读下来也不容易,所以我们要学会抓重点。
首先,论文是什么。是针对于某一个问题或场景,作者提出的解决方案,并且通过实验过程、实验数据、实验分析来验证。所以,一篇文章至少会包括:Title(标题)、Abstract(摘要)、Experiment(实验过程、数据、分析)、Conclusion(结论)。
那么,我们应该重点读哪里呢?。 通过这几部分我们就可以粗略的了解论文内容。
🌰 举例
阅读下面的节选摘要和结论,我们就可以了解到该论文的大概内容。它介绍了如何使用debugbench来解决大模型的debug能力,并且通过从leetcode爬取代码,用GPT-4进行bug植入来构造测试数据集,它覆盖4种bug类型、18种子类型,以及三种开发语言( C++, Java, and Python)。
这不正是小白想要的吗?
摘要节选:
Large Language Models (LLMs) have demonstrated exceptional coding capability.
However, as another critical component of programming proficiency, the debugging capability of LLMs remains relatively unexplored.
Previous evaluations of LLMs’ debugging ability are significantly limited by the risk of data leakage, the scale of the dataset, and the variety of tested bugs.
To overcome these deficiencies, we introduce ‘DebugBench’, an LLM debugging benchmark consisting of 4,253 instances.
It covers four major bug categories and 18 minor types in C++, Java, and Python.
To construct DebugBench, we collect code snippets from the LeetCode community, implant bugs into source data with GPT-4, and assure rigorous quality checks.
结论节选:
In this work, we presented DebugBench, a benchmark specifically designed to evaluate the debugging capabilities of large language models.
DebugBench was developed utilizing source data from LeetCode (LeetCode, 2023) and bug implantation with prompted GPT-4, underpinned by a stringent quality control process.
读完摘要和结论,下一步看什么呢?。俗话说得好,“文不如图,图不如表”。图表里往往包含了非常重要的信息。
🌰举例
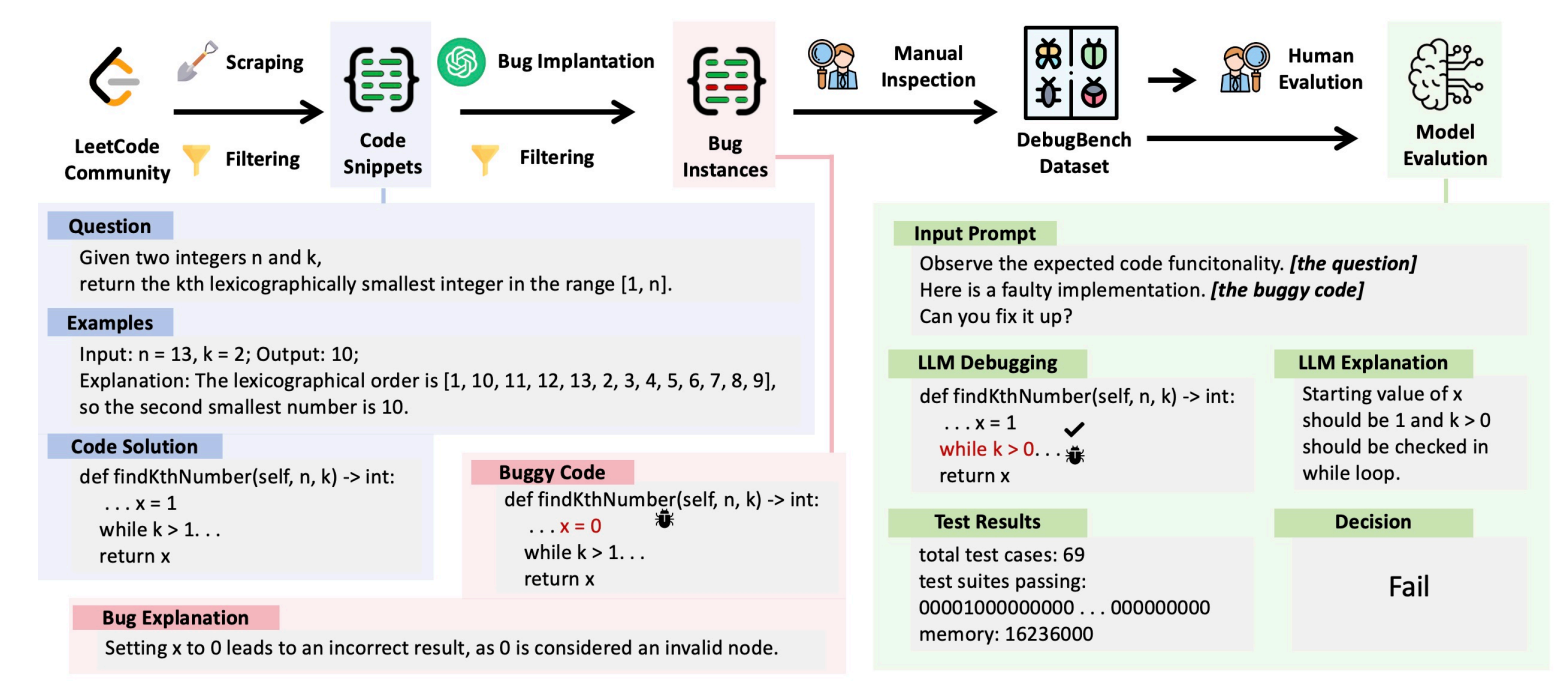
通过图一,我们可以了解测试数据集的构造过程。首先,爬取LeetCode代码得到代码片段(Code Snippets),然后通过大模型(GPT-4)进行代码植入(Bug Implantation),得到错误代码示例(Bug Instances),然后再通过手动检查(Manual Inspection)得到数据集(DebugBench DataSet),最后再对数据集进行人工评估(Human Evaluation)和大模型评估(Model Evaluation) 。
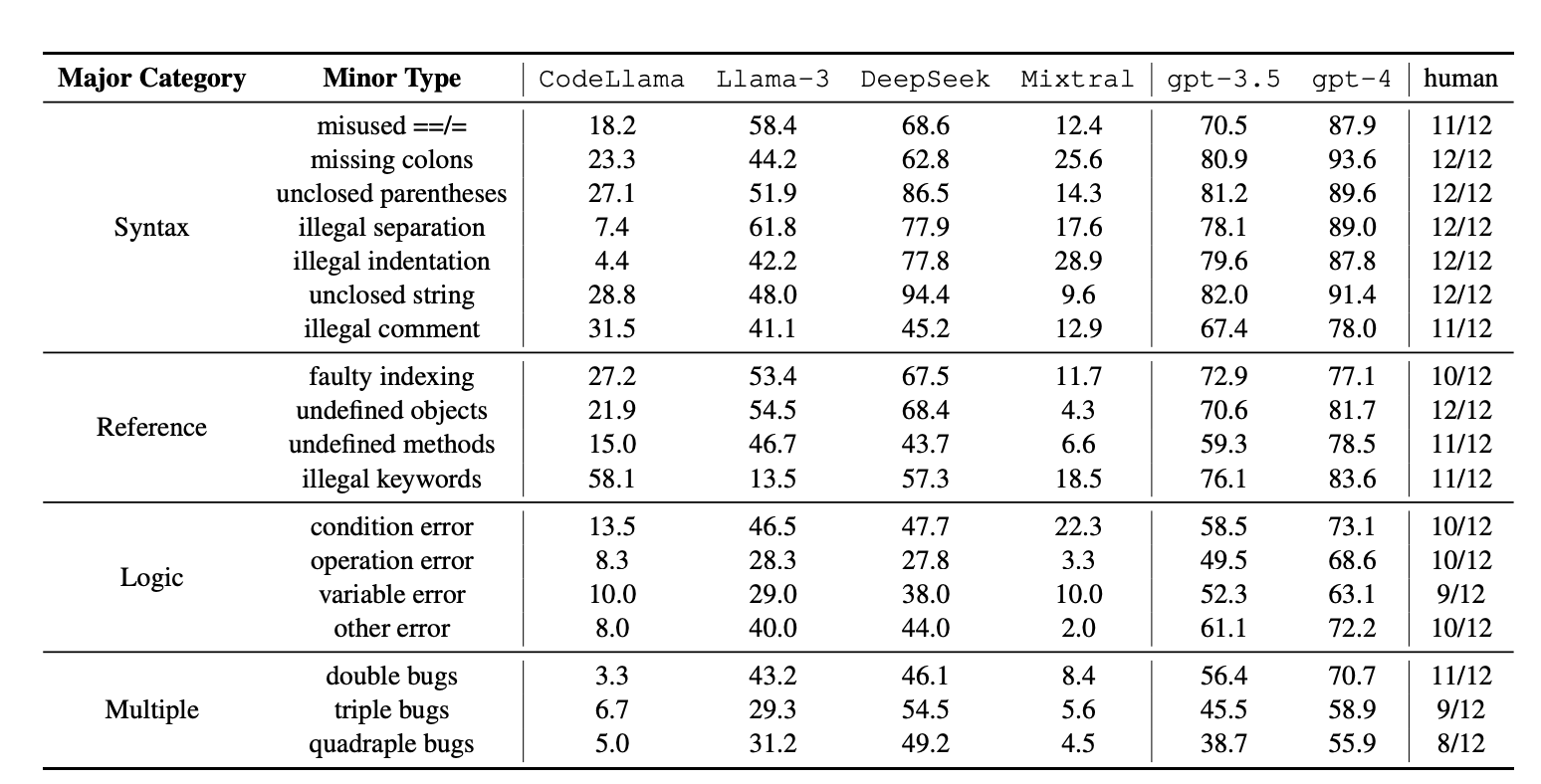
通过图二,我们可以看到作者把bug类型分为四个大类(Major Category)和18个小类(Minor Type),并且对比了六大模型的能力。其中,GPT-3.5、GPT-4的能力明显优于其他四个开源模型,同一模型在语法(Syntax)和引用(Reference)错误比另外两种错误精确率高,每种错误类型的通过率数据等。
3、AI辅助阅读
AI工具有很多,比如前面的提到的“豆包,浏览器AI助手”、还有DeepSeek、元宝,。
它可以获取网页上下文、获取多个网页内容、还可以读取视频。建议直接上手试试。Dia目前只支持Mac、注册需要邀请码。
一开始,我们可以让AI进行总结()、也可以提问我们关注的内容()、也可以进行内容的拓展()。
AI是有幻觉的,所以它的答案并不总是让你满意,这个时候我们就要学会追问和质疑。比如“”(多问几遍)、“”、“”
甚至你还可以让AI去优化AI。比如将豆包的答案丢给DeepSeek、ChatGPT等。问他“”、“”、“”、“”。
你也可以这么问:“” 、“”、“”。
你也可以发挥Dia的优势,比如:”、““、“。
 更多的方法还需要我们多用、多问、多想。
更多的方法还需要我们多用、多问、多想。
4、坚持、坚持、坚持
。分享最近看到的一句话,互勉。

🍁如何找论文
我推荐的方法是,。
1、首先,要明确你的问题或痛点是什么!
2、然后,带着你的问题去问AI,让他推荐对应的开源仓库或者论文。
3、一般开源仓库开头或中间会说自己引用了什么论文(Paper)。
一般我找到的论文都是在这个arxiv网站,打开右上角的View PDF即可。

🌿最后
做AI工程肯定会遇到很多挑战,也需要持续学习,让我们一起祝福小白越挫越勇 、迎难而上、早日变秃变强吧。
🙏🙏🙏感谢您耐心读完。由于本人水平有限,有更好的技巧、工具、想法可以在评论提出,也可以偷偷小窗私我哈。